Module 4 (Databases & SQL)
 Photo by Pawel Czerwinski on Unsplash
Photo by Pawel Czerwinski on UnsplashDatabases & SQL
Database types
There are mainly 2 different types of databases: Relational databases (SQL) or non-relational databases (NoSQL)
Relational databases
SQL basically means structured query language or in other words relational databases have a good structure in it. This structure is made up by tables which contain rows, columns and data points. So for example if we want to know something about weather then we can call the table “Weather”. For this example then the colums could be the days of the week, the rows could be the time of the day and between the data points consist of the temperature which was at this point in time.
For further explanations each row has a unique ID while the columns hold attributes. So each record has an attribute to it. This makes it easy for data points to see relations and seperate them from the physical storage structures. Negative points regarding relational DBs are that they are poor at handling simultaneous data requirements and frequent changes.
NoSQL databases
The opposite of relational databases are NoSQL databases which are less structured. They are more like a data collection in which you can find every data you saved but without having a realtion to something else or keyword. But NoSQL DBs can other than relational ones handle a lot of traffice. Negative aspects are that they aren’t good for consistency.
Relationships
There are 3 different types of realtionships:
- One-to-One (1:1) -> only one data point belongs to one unique other data point and vice versa
- One-to-Many (1:n) -> one data point belongs to many others but these others only belong to a single one
- Many-to-Many (n:n) -> many data points can belong to many other data points (books <-> author)
How data can be stored inside a database
ACID
ACID stands for A(tomic), C(onsistent), I(solated) and D(urable). Those 4 key points mean:
- Atomic -> Every data transaction has to be made (valid and successful done) or otherwise nothing should be changed
- Consistent -> The whole data has to be in a consistent state at any time
- Isolated -> No parallel processes that can change data at the same time
- Durable -> changes made to datasets have to persist
This concept is mainly used for distributed databases. For NoSQL databases the BASE principle is used (Basically Available, Soft state, Eventual consistency).
CAP
If a DB has to fulfill all ACID properties and additonally must have a high availability there are some other problems phrased in the CAP theorem. CAP is a triangle relationship from which only two can occur at a time. This three properties are:
- data consistency (C)
- system availability (A)
- partition tolerance (P)
DBs that need to have a high availabilty (mostly distributet systems) will focus more on CA while modern NoSQL more focus on CP to have a high scalability. Therefore to it has no fix solution to answer the question on how to store data inside a database. It’s much more a weighting on what interests you have or what requirements you have for a system.
Database system
Consists of:
- Types
- Concepts
- Objects
- Components
- Functions
- Related topics
But it also has to be secured in a good manner. Otherwise it could be attacked by malicious hackers or other people and therefore you can loose data.
Security problems
Imagine you would have a Swiss SME company which produces personalized and customized implatable chips. For that you need a database where every persons medical history as well as other specifications about the persons body gets saved. For this reason you should secure your database correctly so hackers or other people with malicious intentions can’t steal, modify or even delete the data in your system.
In my opinion I would therefore implement a few security features/implementations to mitigate the risks:
Database-level roles
- Used to give different persons different roles/rights
- You can easily add or remove permissions to/from someone
- Through this implementation unpleased changes for critical data or settings can’t be made accidentally
File encrypton
- Protects data from being red by someone that hasn’t the privileged rights
- Attacker can’t just steal physical saving medium
SQL injection prevention
- Review/audit every SQL code
- Devs and admins only should be able to execute code/files
- Disallow critical input characters
Password security
- Every user has to choose a good and safe password (over 15 signs, includes special characters, numbers and big letters, random generated not personal)
- Disable SA logins
- Don’t save passwords somewhere unsecured
Ransomeware protection
- Always install newest security updates
- Avoid unrequired installations/services
- Provide a strong firewall
- Pay special attention to RDP and SSH vulnerabilities
Ordering structure in a database
So basically DBs are normally to get easier access on datasets/files. This is in most cases for structured data. But what exactly is structured data? Data can be differentiated to 3 different categories of structuring levels:
- Unstructered -> normal textfile
- Semi-structured -> XML, HTML etc.
- Structured -> Excel, table with rows and columns
Database and it’s usecase
A database can be used to save data in a structured way as a collection of tables. To run a DB you have to use a DBMS (database managment system) combined with a query language f.e. SQL to access it.
It makes data accessible in an easy way, can handle specific information requests (because of it’s structured way) and saves data/files over a longer period of time without the need of electricity. Examples of data you would store in a DB:
- Preferences of articles from persons in an online store
- Pre-diseases of clients
Exmaples where you don’t want to use a DB:
- Duplicated data
- Files such as images
- Critical credentials
MySQL
Everything you want to do on a RDBMS is done with the help of SQL. Statements / commands you write in SQL is normally defined into 2 groups:
- DDL statements (Data Definition Language) -> Creating or deleting tables and rename columns
- DML statements (Data Manipulation Language) -> Add, delete or update rows
In the module I have a few exercises for learning the handling of a DB. For this we use the programming language MySQL. After the download of the workbench and some simple code statements I already created my first DB (without something in it so far).
Created my first database
Some basic commands you use for programming with MySQL:
- CREATE DATABASE name -> creates a new DB
- USE name -> switches into a DB
- DROP DATABASE name -> deletes a DB
- SHOW TABLES -> shows all tables inside the DB
- CREATE TABLE IF NOT EXISTS name ( columnname1 VARCHAR(length) PRIMARY KEY, columnname2 VARCHAR(length), columname3 [after the name you can specific any datatype] etc. -> creates a table with given specifications
- SELECT columname FROM tablename -> shows the values of the selected column
- SELECT * FROM tablename -> selects every column
- WHERE condition -> specifies what it should select f.e. CustomerID > 5 then it selects every customerid bigger then 5
- AND, OR, NOT -> can all be used to specify the WHERE statements more detailed
- ORDER BY columname ASC/DESC -> oders the values in an ascending/descending order
- INSERT INTO tablename (columnname) + VALUES (value1, value2, etc.) -> inserts the values in a new row at the last place of the DB
- UPDATE tablename + SET columnname = value1, etc. + WHERE condition -> modfies existing records without the WHERE statement it updates the whole column
- DELETE FROM tablename + WHERE condition -> will delete the whole record
- WHERE columname + LIKE pattern -> WHERE in combination with LIKE to search for a specific patter f.e. a% (everything that starts with a), %a% (everything that has an a somewhere in it), a__% (everything that starts with a and has at least 2 characters in length)
And for the columns there are different types of data which you can put in as well. From characters to booleans, text, dates etc. For our example we have already given names for the columns and need to specify the types which would fit the best for the specific column. One exercise is therefore to assign different example columns different data types. Here my solution:
- First name: CHAR
- Last name: CHAR
- Street name: CHAR
- PLZ: TINYINT
- City: CHAR
- Phone number: TINYINT
- Image: LONGBLOB (or for SQL server image)
DB Creation
So to get started I already created my own DB with the MySQL database. I got a short introduction and red some commands to help me getting a feeling for how the code works. After that I implemented my first table into the newly created DB.
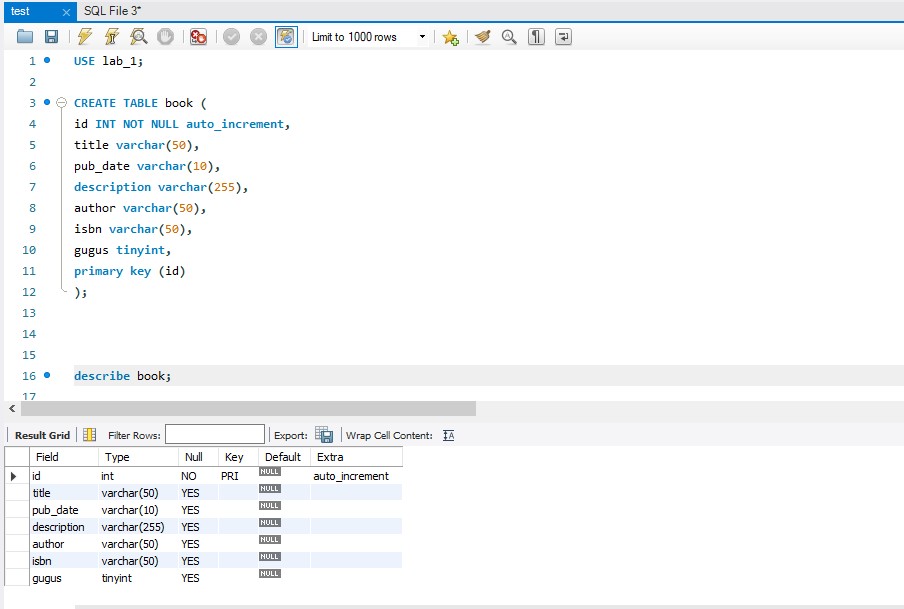
Created my first table for a book DB
Later I had to add 5 books of my choice with all the information that was needed to fill the columns. This also included a certain play around with commands to get known with MySQL (commands I used were: ALTER, INSERT, SELECT, WHERE, UPDATE and DELETE as well as a few subcommands). Here some images of what I’ve done with them in the workbench.
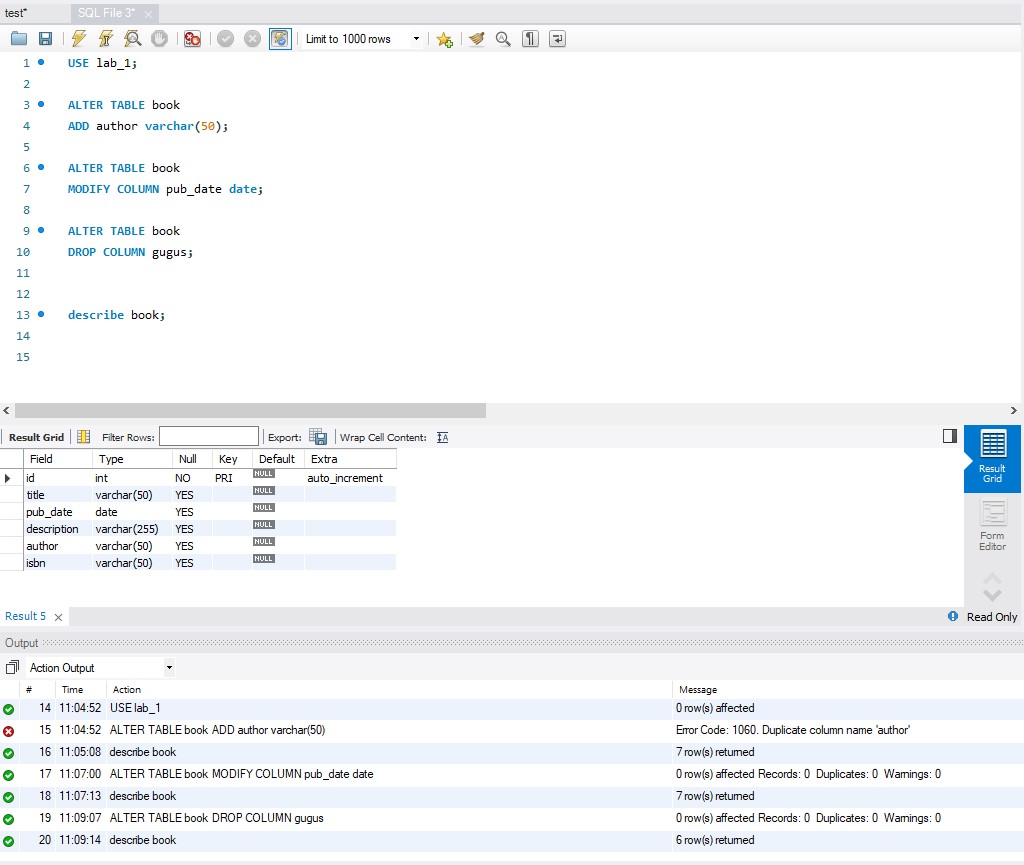
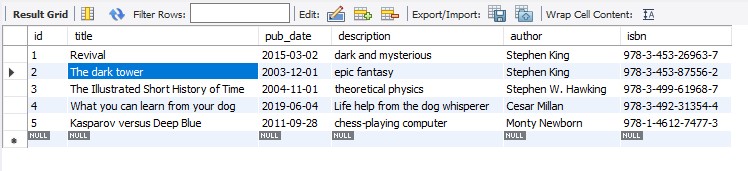
Modified columns of the book table
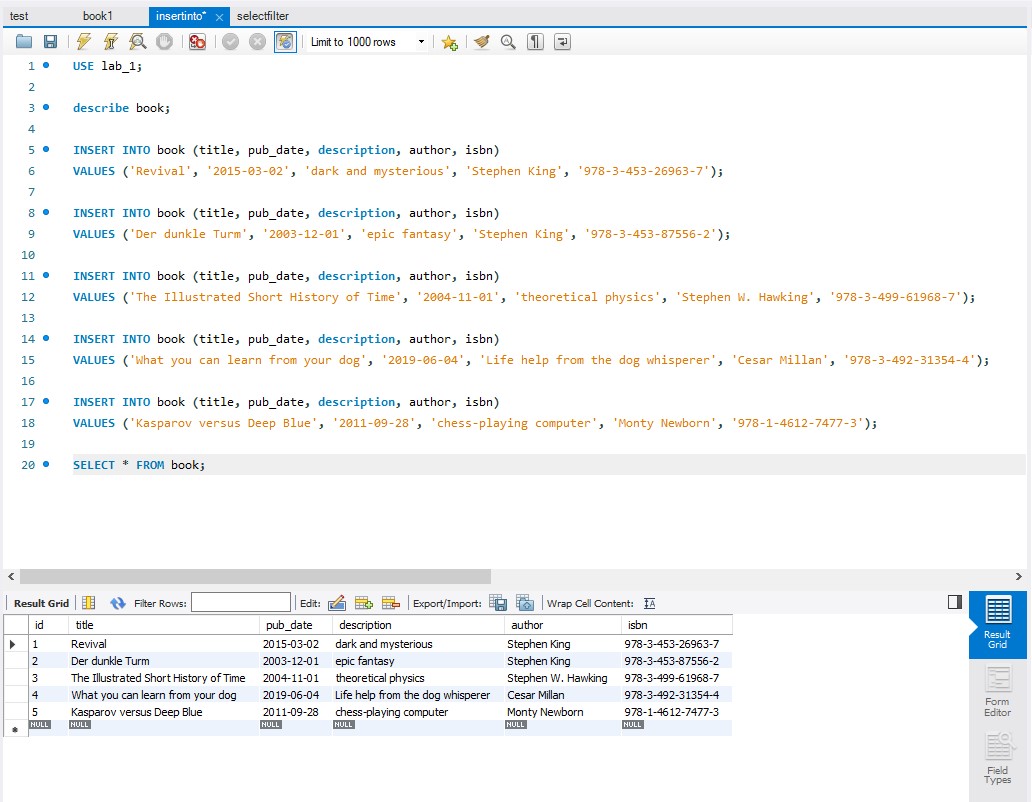
Filled in the informations for the columns / added 5 books to the table
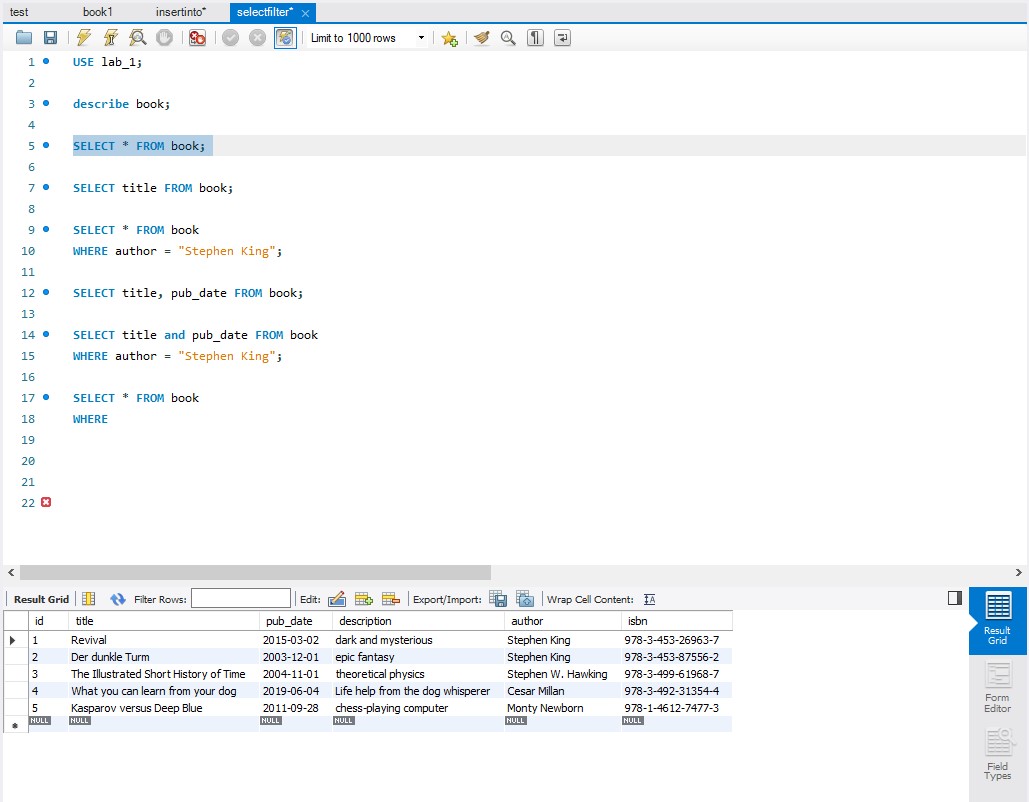
Selected all newly created rows
Specific selection of the table data points
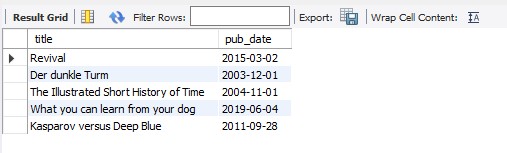
Updated a value in the table
Normalization
Normalization is a process that follows specific steps/norms to make a DB more efficient and logical. It’s intended for making a DB structured and also doesn’t hold duplicated data (eliminating redundancy and inconsistent dependency). To achieve this there are 10 forms which are more likely formal rules which should be implemented while creating a DB. We will look at the most common ones which are the first 4:
UNF -> Unnormalized form
- no duplicated rows
- columns have unique names
1NF -> First nomral form
- hold only atomic values -> single value in one cell
- Solution 👉 You make a new row for every cell that contains more then one value
2NF -> Second normal form
- composite keys -> takes more then one column to make the row unique
- partial dependence -> if there are more columns besides the composite key and some of these columns only have a dependecy to one part of the composite key then it’s a partial dependence
- Solution 👉 You identify the composite key (if it has one) and watch for all other columns if they have only a partial dependence. If yes, then you make a new table for that column together with the part of the composite key used as primary key in the new table.
3NF -> Third normal form
- transitive dependence -> if it needs more than one step to get to the data point in a column therefore it’s possible to have duplicated data
- Solution 👉 Make a new table for the second step.
DB modelling
How a DB should be structured and built up is mostly done with models. These models follow some specific schemas you want to document. There are mainly 2 types of models:
- RM (Relational Model)
- ERM (Enity-Relationship Model)
RM
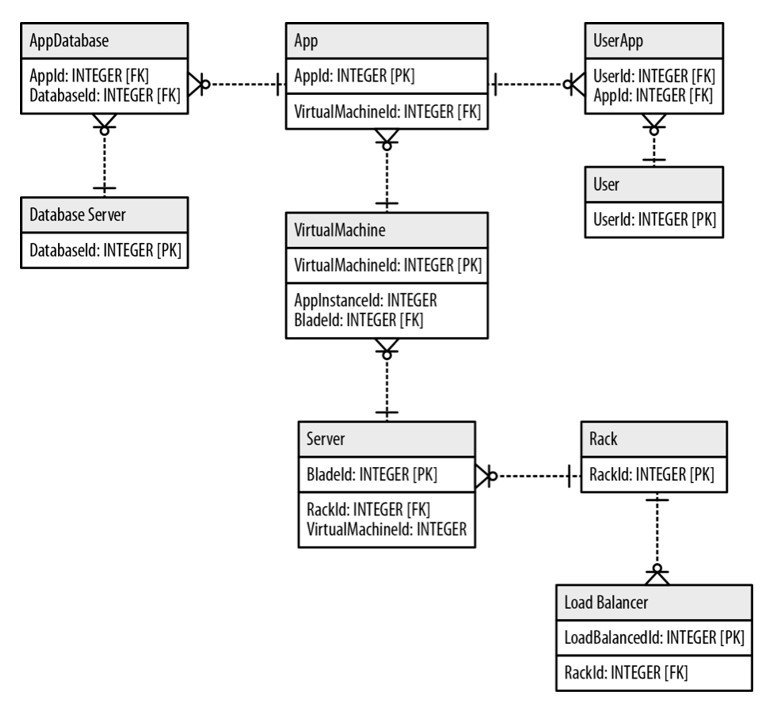
Example of an RM modelling
- Every box is a table of the DB
- Mainly focused on the tablename and the primary key and foreign keys
- No additional information
- Relations can be made with arrows or the crow’s food notation
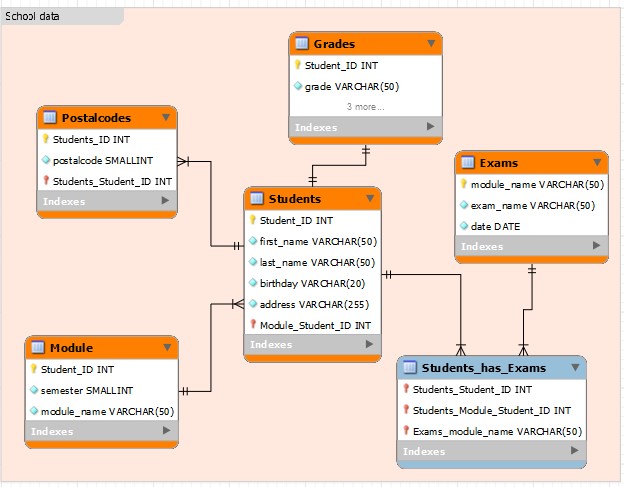
Selfmade RM of school data